随着大数据技术的快速发展,公安行业对实时数据处理和运维的需求日益增长。基于Spark的公安大数据实时运维技术实践,结合了其分布式计算能力和实时处理框架,为公安业务提供了高效、可靠的数据处理服务。以下从数据处理服务的架构、关键技术和实践应用三个方面进行分析。
一、数据处理服务架构分析
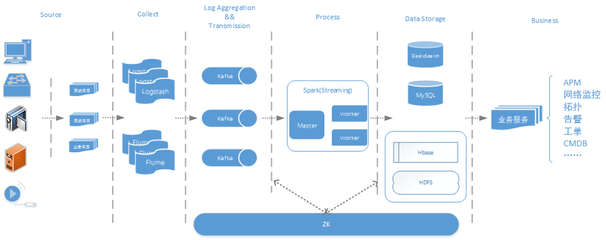
公安大数据实时运维的数据处理服务通常采用分层架构,包括数据采集层、数据处理层和数据服务层。数据采集层负责从各类公安业务系统(如视频监控、案件记录)实时收集数据;数据处理层基于Spark Streaming或Structured Streaming构建,实现数据清洗、转换和聚合;数据服务层则通过API或可视化工具,向公安用户提供实时分析结果。这种架构确保了数据从采集到服务的端到端实时性。
二、关键技术分析
- 实时流处理技术:Spark Streaming和Structured Streaming是核心组件,支持高吞吐、低延迟的流数据处理。在公安实践中,通过窗口操作和状态管理,实现对实时数据(如车辆轨迹、人员流动)的连续监控和分析。
- 数据集成与存储:公安数据来源多样,需整合结构化与非结构化数据。Spark可与Kafka、HDFS等系统集成,实现数据高效摄入;同时,利用Spark SQL和DataFrame API进行数据标准化,确保数据质量。
- 运维监控与容错:Spark的容错机制(如RDD血统)和集群管理工具(如YARN或Kubernetes)保障了服务的稳定性。实践中,需部署监控系统(如Prometheus)跟踪数据处理性能,并通过报警机制及时处理异常。
- 安全与合规:公安数据涉及敏感信息,Spark需结合加密、访问控制等技术,确保数据安全。例如,通过Kerberos认证和审计日志,满足公安行业的合规要求。
三、实践应用分析
在公安场景中,基于Spark的数据处理服务广泛应用于实时预警、案件分析和资源调度。例如,通过实时分析交通流量数据,优化警力部署;或利用机器学习模型(集成Spark MLlib)进行异常行为检测。实践表明,Spark的高可扩展性能够应对公安数据量的快速增长,同时其社区支持和开源生态降低了开发成本。
基于Spark的公安大数据实时运维技术实践在数据处理服务中展现出强大优势,通过合理的架构设计、关键技术应用和场景适配,提升了公安业务的实时响应能力和决策效率。未来,随着AI和边缘计算的融合,该技术将进一步优化,服务于更复杂的公安需求。