在HCIP数据库服务规划的学习中,数据处理服务是核心模块之一,它涵盖了数据从采集、处理到应用的完整生命周期管理。本文将围绕数据处理服务的规划要点展开,梳理关键概念、技术选型与设计原则。
一、数据处理服务概述
数据处理服务主要关注数据在系统内的流动与转换,旨在将原始数据转化为有价值的信息,支撑业务决策与应用。其核心流程通常包括数据抽取、清洗、转换、加载(ETL)以及实时流处理等环节。在规划时,需根据业务场景(如OLTP在线交易、OLAP分析或实时监控)确定处理模式,例如批量处理适合历史数据分析,而流处理则适用于实时风控或推荐系统。
二、关键技术选型与规划
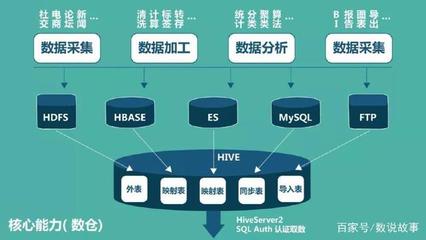
- 数据存储与计算框架:根据数据规模与处理需求,可选择Hadoop生态(如HDFS存储与MapReduce计算)处理海量离线数据,或使用Spark进行内存加速分析。对于实时场景,Flink或Storm等流处理框架更为合适。规划时需评估集群资源、扩展性及运维成本。
- ETL工具与流程设计:常用工具如Apache NiFi、Kettle或云服务商提供的DataWorks。规划重点在于设计高效的数据管道,包括数据源连接、去重、格式标准化等步骤,并确保数据质量与一致性。
- 实时数据处理架构:若业务需要低延迟响应,可采用Kafka作为消息队列,配合流处理引擎实现实时计算。规划时需考虑数据吞吐量、容错机制(如检查点设置)与端到端延迟指标。
三、数据处理服务规划原则
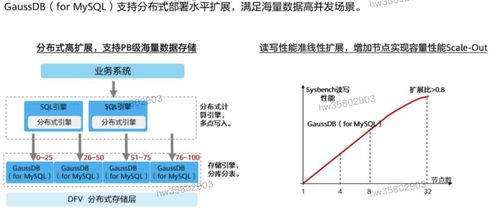
- 可扩展性:设计应支持水平扩展,以应对数据量增长。例如,采用微服务架构将处理模块解耦,便于独立扩容。
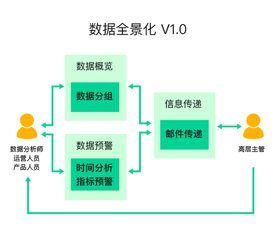
- 可靠性:通过冗余部署、故障转移机制(如集群备份)保障服务连续性。对于关键数据流,需实施监控告警与自动恢复策略。
- 安全性:规划中需集成数据加密、访问控制(如RBAC角色权限管理)及审计日志,防止数据泄露或篡改。
- 成本优化:根据数据处理频率与时效性,合理选择资源类型(如按需实例或预留资源),并利用数据分层存储(热数据SSD、冷数据归档)降低开销。
四、实践案例与注意事项
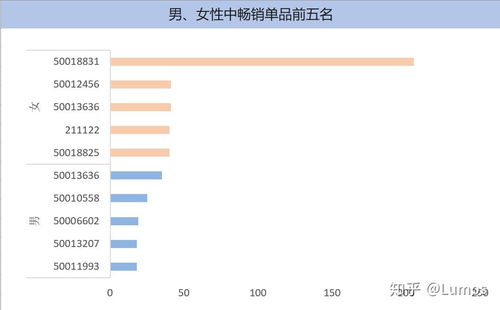
以电商场景为例,数据处理服务可能包括:用户行为日志的实时采集(通过Flume/Kafka)、订单数据的批量ETL(每日同步至数据仓库)、以及基于Flink的实时推荐计算。规划时需注意:
- 明确业务指标(如处理延迟低于1秒),并以此设计架构。
- 进行性能压测,验证数据处理峰值承载力。
- 制定数据治理策略,包括元数据管理、血缘追踪,便于问题排查与合规审计。
五、
数据处理服务是数据库服务规划的关键支柱,其设计需紧密贴合业务目标与技术生态。通过合理选型、遵循扩展与安全原则,并结合持续监控优化,可构建高效、稳定的数据处理体系,为上层应用提供坚实的数据支撑。在学习与实践中,建议多参考行业案例,并注重动手搭建实验环境以深化理解。